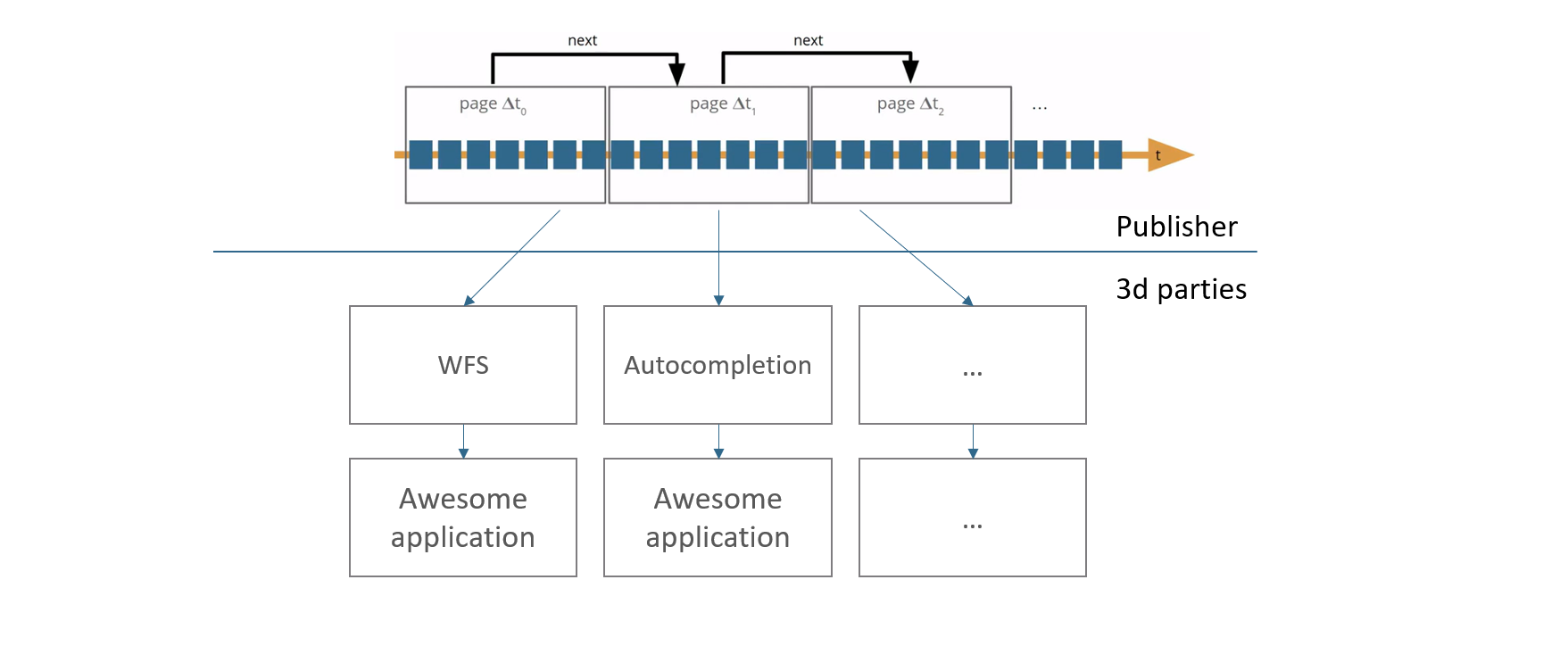
Introduction to Linked Data Event Stream
Today, the main task of data publishers is to meet the user’s needs and expectations, and they realise this by creating and maintaining multiple querying APIs for their datasets. However, this approach causes various drawbacks for the data publisher. First, keeping multiple APIs online can be costly as the load generated by data consumers is often at the expense of the data publisher. And second, data publishers must ensure their APIs are always up-to-date with the latest standards and technologies, which results in a huge mandatory maintenance effort.
As new trends emerge, old APIs may become obsolete and incompatible, creating legacy issues for data consumers who may have to switch to new APIs or deal with outdated data formats and functionalities. Moreover, the existing APIs limit data reuse and innovation since the capabilities and limitations of these APIs constrain data consumers. They can only create their views or indexes on top of the data using a technology they prefer.
“Linked Data Event Streams as the base API to publish datasets”
On the other hand, data consumers often have to deal with multiple versions or copies of a dataset that need to be more consistent or synchronised. These versions or copies may have different snapshots or deltas published at other times or frequencies. Although using data dumps provides a data consumer with complex flexibility regarding the needed functionality, this approach also has various drawbacks. For example, data consumers must track when and how each version or copy was created and updated. They also have to compare different versions or copies to identify changes or conflicts in the data. Data consumers may need to be more consistent due to outdated or incomplete versions or copies. They may also miss significant changes or updates in data not reflected in their versions or copies.
To overcome these challenges, Linked Data Event Streams (LDES) provide a generic and flexible base API for datasets. With LDES, data consumers can set up workflow to automatically replicate the history of a dataset and stay in sync with the latest updates.