
Ontwikkelaars bouwen applicaties op basis van vooraf beschreven informatiemodellen en business-vereisten. Vier cases komen aan bod die de stappen beschrijven die een ontwikkelaar kan toepassen bij het gebruik van OSLO.
Case 1: Een API opzetten
REST en RDF, de technologie die Linked Data onderbouwt, delen een aantal fundamentele principes:
- Aan de basis van informatie ligt het concept ‘resource’;
- Maken gebruik van HTTP(S) en HTTP(S) URI’s;
- Zelfbeschrijvend, er is geen voorkennis nodig om de relaties tussen resources te begrijpen;
- Geschikt voor Domain Driven Design.
In combinatie zijn ze in staat om resources (data) te ontsluiten samen met het achterliggend informatiemodel, gebruik te maken van meer gesofisticeerde semantiek voor state-transitions en het Web of Data write-enabled te maken.
De W3C Recommendation Linked Data Platform is een specificatie die patronen aanreikt om RESTful HTTP services te bouwen die in staat zijn om read-write operaties uit te voeren op Linked Data. Daarnaast wint een specificatie in opbouw, Hypermedia Driven Web APIs (HYDRA), aan populariteit om Linked Data principes toe te passen op REST API’s door een vocabularium van termen aan te reiken waarmee generieke API clients gemaakt kunnen worden. Tot slot is het mogelijk om bestaande REST API’s die gebruik maken van JSON om te vormen met minimale inspanning door een @context definitie mee te geven in de HTTP Link Header. Meer informatie hieromtrent is terug te vinden in de JSON-LD specificatie.
Case 2: Een database opzetten
Bij het opzetten van een database worden volgende zaken best in acht genomen:
- Gebruik van NoSQL databases.
Linked Data is gebaseerd op graph data, waarbij in tegenstelling tot een relationeel of hiërarchisch data model, objecten rechtstreeks aan elkaar gelinkt worden, via relaties, en deze relaties ook rechtstreeks deel kunnen uitmaken van een query.
Voorbeeld: relationeel versus graph data model.
Relationele data:
Graph data:NoSQL databases zoals MongoDB, CouchDB, Neo4J, Virtuoso en Redis zijn dankzij hun performantie en flexibiliteit om complexe semi-gestructureerde data op te slaan meer geschikt dan traditionele relationele databases om Linked Data applicaties te onderbouwen.
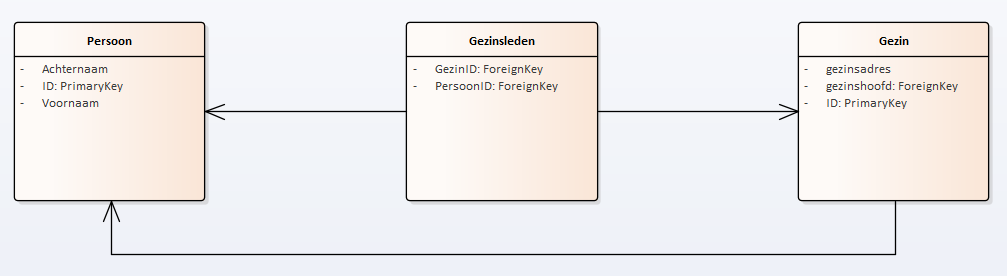
Voorbeeld: query voor het ophalen van gezinsleden voor een specifiek persoon in SQL (relationeel) vs. SPARQL (graph).
SQL
SPARQL
Voor ondervragingen is SPARQL in dit geval compacter dan de traditionele relationele database query. Desalniettemin maken relationele databases het beheer (write) makkelijker omdat transacties een duidelijke betekenis hebben.
- Gebruik van Triplestores
Triplestores vormen een subset van NoSQL databases waar informatie wordt opgeslagen als triples en opgevraagd kan worden door gebruik te maken van semantische queries met behulp van de query-taal SPARQL. Ze onderscheiden zich van andere NoSQL databases doordat ze efficiënt gebruik kunnen maken van URIs als identifiers. Daarnaast bieden triplestores native ondersteuning voor het gebruik van meerdere namespaces (meerdere informatiemodellen) door elkaar en het afleiden van niet-expliciete relaties door inferentie van het informatiemodel. Dit maakt triplestores uitermate geschikt om centraal informatie bij te houden uit meerdere bronnen met elk een eigen informatiemodel en waar bovendien veel relaties tussen de verschillende objecten bestaan. Er bestaan zowel open source triplestores zoals Apache Jena Fuseki en OpenLink Virtuoso, als commerciële varianten zoals Neptune, dat onderdeel uitmaak van Amazon Web Services.
Wanneer een triplestore gebruikt wordt in combinatie met een SPARQL endpoint om gegevens te ontsluiten kan dit resulteren in een zware belasting van de server, in het bijzonder wanneer meerdere requests tegelijk behandeld moeten worden. Om de performantie te verbeteren, kan gebruik gemaakt worden van caching technieken als Linked Data Fragments.

Case 3: Gegevensuitwisseling
Naast een semantisch afgestemd informatiemodel heeft een toepassing nood aan een concrete methode voor gegevensuitwisseling. Een mogelijk formaat om semantiek mee te geven in API payloads is JSON-LD (JSON Linked Data). JSON-LD laat ontwikkelaars toe om applicaties en diensten die gebruik maken van JSON, met een minimale inspanning Linked Data enabled te maken.
De stabiele JSON-LD 1.0 specificatie werd gepubliceerd door W3C als een Recommendation. De meest recente specificatie en documentatie is te vinden op json-ld.org. JSON-LD kenmerkt zich door het toevoegen van volgende elementen aan een klassiek JSON object:
- @context: bevat een oplijsting van keys die doorheen het JSON(-LD) object gebruikt worden samen met een link (IRI) die verwijst naar hun definitie en indien relevant een type die aangeeft wat de verwachte value is voor deze keys. Op deze manier wordt de “context” meegegeven aan de ontvanger van het JSON object.
- @id: een unieke identificator voor objecten.
- @type: bepaalt het type van het object of de node en kan ook meegegeven worden in de context.
Voor een volledige uiteenzetting van de specificatie verwijzen we naar JSON-LD 1.0.
De W3C Recommendation Linked Data Platform is een specificatie die patronen aanreikt om RESTful HTTP services te bouwen die in staat zijn om read-write operaties uit te voeren op Linked Data. Daarnaast wint een specificatie in opbouw, Hypermedia Driven Web APIs (HYDRA), aan populariteit om Linked Data principes toe te passen op REST API’s door een vocabularium van termen aan te reiken waarmee generieke API clients gemaakt kunnen worden. Tot slot is het mogelijk om bestaande REST API’s die gebruik maken van JSON om te vormen met minimale inspanning door een @context definitie mee te geven in de HTTP Link Header. Meer informatie hieromtrent is terug te vinden in de JSON-LD specificatie.
Gebruik van @context definities
De @context heeft als doel de semantiek samen met de data te ontsluiten. Dit kan op verschillende manieren gebeuren:
- Hergebruik van bestaande context definitie
Voor OSLO vocabularia bestaan herbruikbare context files in JSON-LD formaat waar naar verwezen kan worden vanuit een JSON-LD object.
OSLO vocabularium Context file Generiek http://data.vlaanderen.be/context/generiek.jsonld Adres http://data.vlaanderen.be/context/adres.jsonld Persoon http://data.vlaanderen.be/context/persoon.jsonld Organisatie http://data.vlaanderen.be/context/organisatie.jsonld Dienst http://data.vlaanderen.be/context/dienst.jsonld
Voorbeeld: hergebruik van OSLO context definitie.
- Combineren van meerdere context definities
In vele gevallen is het mogelijk dat meerdere entiteiten uit verschillende vocabularia in hetzelfde JSON-LD object voorkomen. Daarom is het mogelijk om ook meerdere context referenties mee te geven in hetzelfde JSON-LD object. In het geval dat bepaalde termen overlappen, zal de laatst gedefinieerde term (in onderstaand voorbeeld uit de adres context) voorgaande termen met dezelfde benaming overschrijven.
Voorbeeld: hergebruik van OSLO context definitie.
- Gebruik van eigen termen
Wanneer een bestaande API zijn informatie wil ontsluiten conform de OSLO semantische informatiemodellen als JSON-LD, zonder de reeds gebruikte keys aan te passen, kan er voor gekozen worden om een eigen context file te creëren. Het blijft evenwel een vereiste om eerst het semantisch afstemmingstraject te doorlopen. Voor meer informatie met betrekking tot het creëren van een context file refereren we naar de JSON-LD specificatie. Voor bestaande API’s kan de context definitie meegegeven worden in de HTTP Link Header in plaats van als onderdeel van de payload.
Voorbeeld: hergebruik van OSLO context definitie.
- Bestaande context definitie uitbreiden
Indien een JSON-LD object gebruik maakt van zowel OSLO als andere entiteiten, en indien deze andere entiteiten relevant zijn voor de uitwisselingen van informatie met andere toepassingen of agentschappen, kan een bestaande OSLO @context uitgebreid worden met nieuwe termen.
Voorbeeld: OSLO context definitie voor persoon uitbreiden met nieuwe termen van het FOAF vocabularium voor het weergeven van een profielfoto.
Verduidelijking: Het is ook mogelijk om in een JSON-LD object gewone JSON attributen mee te geven, zonder deze te definiëren in de @context. Wanneer het object als JSON-LD geparsed wordt, zullen termen die niet voorkomen in de @context genegeerd worden. De term zal dus enkel beschikbaar zijn voor de lokale applicatie, binnen de bounded context. - Overschrijven van context definities
In JSON-LD is het mogelijk om de definitie van termen te overschrijven. Dit is vooral relevant wanneer een bestaande API omgevormd wordt zonder de JSON-structuur aan te passen én wanneer bepaalde keys een andere betekenis hebben afhankelijk van het niveau waarop ze voorkomen.
Voorbeeld: de eigenschap ‘plaats’ heeft afhankelijk van waar het voorkomt in het JSON-LD object, ofwel als verwacht type ‘GeografischePlaats’, wat de standaard optie is in OSLO en dus ook in de OSLO context definitie voor persoon staat, of ‘Adresvoorstelling’. In onderstaand voorbeeld wordt ‘GeografischePlaats’ als type gebruikt voor plaats onder ‘inwonerschap’ en overschreven met ‘Adresvoorstelling’ in de context definitie onder ‘heeftGeboorte’.
Omgaan met identificatoren
In Linked Data, en zo ook in JSON-LD, wordt als identificator voor een object waar mogelijk gebruik gemaakt van een URI (uniform resource identifier). In JSON-LD kan elk ‘node object’ een eigen identificator hebben, aangeduid met de key “@id”. Om hier invulling aan te geven kan gebruik gemaakt worden van absolute URI’s, relatieve URI’s of ‘blank node identifiers’.
Bij Absolute URI’s wordt de volledige URI meegegeven als waarde van de “@id” key.
Wanneer de value van de “@id” key niet start met http(s) wordt de string geïnterpreteerd als een relatieve URI. Als basis wordt dan de URI van de request header genomen. Alternatief kan in de context definitie ook een ‘base URI’ vastgelegd worden.
Een blank node identifier is een string die dienst doet als identificator voor een blank node object. Een blank node identifier is een lokale identificator en is niet persistent, waardoor ze niet bruikbaar zijn buiten de applicatie of service waar ze hun oorsprong vinden. Blank node identifiers hebben steeds _: als prefix, opdat ze niet als relatieve URI zouden geïnterpreteerd worden.
Nesting en arrays
In JSON-LD wordt het nesten van objecten gebruikt om relaties tussen objecten weer te geven, niet om een hiërarchisch verband voor te stellen. Elk genest object kan bijgevolg ook een eigen “@id” en “@type” hebben.
Net zoals bij JSON kunnen arrays weergegeven worden door gebruik te maken van vierkante haakjes. In tegenstelling tot JSON, zijn bij JSON-LD arrays standaard niet geordend. Om het concept van collecties te bewaren kan gebruik gemaakt worden van @list.
Definiëren van codelijsten, taxonomieën en thesauri
Het Simple Knowledge Organisation System (SKOS) is een generiek datamodel voor het delen van controlled vocabularies zoals codelijsten, thesauri en taxonomieën in een machine-leesbaar formaat op het Web. Het beschikbaar maken van codelijsten volgens SKOS brengt enkele voordelen met zich mee:
- De-referencing: de principes van Linked Data zijn ook van toepassing op codelijsten en stellen dat elke term in een codelijst moet corresponderen met een URI op basis van het HTTP protocol. Mensen die een term uit een codelijst tegenkomen kunnen dan makkelijk de betekenis opzoeken door de URI in te voeren in een web browser.
- Machine-leesbaarheid: via de URI kan zowel een machine- als mens-leesbare versie van de codelijst worden opgehaald. SKOS is bovendien een W3C Recommendation, wat interoperabiliteit bevordert met andere systemen die SKOS implementeren.
- Meertaligheid: SKOS laat toe om makkelijk labels en definities in meerdere talen toe te voegen.
Een codelijst kan in SKOS worden voorgesteld door gebruik te maken van de volgende klassen, eigenschappen en relaties:
- skos:ConceptScheme: de codelijst zelf kan voorgesteld worden als een skos:ConceptScheme.
- skos:Concept: elke term in de codelijst is een instantie van de klasse skos:Concept.
- skos:hasTopConcept: deze eigenschap laat toe om een hiërarchie in een codelijst te stoppen, bijvoorbeeld types en subtypes, door voor een skos:ConceptScheme aan te duiden welke termen zich op het hoogste niveau bevinden.
- skos:inScheme: deze eigenschap laat toe om vanuit een bepaalde term (een skos:Concept) aan te geven bij welke codelijst deze behoort.
- skos:definition: deze eigenschap laat toe om een definitie (in tekstvorm) mee te geven aan een terms in de codelijst (een skos:Concept).
- skos:notation: deze eigenschap laat toe om aan een bepaalde term een code toe te kennen.
- skos:prefLabel: het (mens-leesbare) label dat geassocieerd is met de term.
Containers en paginering
Soms is het nodig om in één JSON(-LD) document meerdere top-level objecten mee te geven die allen dezelfde context delen als antwoord op een specifieke API request. Bijvoorbeeld om een overzichtspagina te maken of een oplijsting van objecten te tonen met een bepaalde filter erop toegepast. In deze gevallen kan gebruik gemaakt worden van HYDRA. De HYDRA specificatie voor hypermedia-driven Web APIs laat toe om meer informatie mee te geven aan een container, specifiek voor het aansturen van REST APIs, in lijn met de principes van Linked Data.
Input of output structuur vastleggen met JSON-LD framing
JSON-LD framing is een techniek waarbij ontwikkelaars een bepaalde structuur (een frame) kunnen opleggen aan het JSON-LD payload. Er kan onder meer een onderscheid gemaakt worden tussen verplichte en optionele nodes en standaardwaarden voor attributen kunnen worden meegegeven. Op die manier kan consistentie gegarandeerd worden en kunnen deze frames dienen als basis voor tests, validatie en het toelaten van meerdere datastructuren langs input zijde. Het Framing Algoritme is bovendien in staat om JSON-LD objecten om te zetten naar de gewenste structuur. Voor meer details verwijzen we naar de specificatie.
Beschikbare tools en libraries
Er bestaan tools en libraries voor de meeste web-programmeertalen. Onderstaande tabel geeft een overzicht van JSON-LD processors en API’s in verschillende programmeertalen.
| Programmeertaal | Wat? | Link |
| JavaScript | JSON-LD Processor en API library | https://github.com/digitalbazaar/jsonld.js/ |
| Java | JSON-LD Processor en API library | https://github.com/jsonld-java/jsonld-java |
| .NET | JSON-LD Processor | https://github.com/NuGet/json-ld.net |
| PHP | JSON-LD Processor en API library EasyRDF Library voor RDF manipulatie (met ondersteuning voor JSON-LD) |
https://github.com/digitalbazaar/php-json-ld http://www.easyrdf.org/ |
| NodeJS | JSON-LD Processor | https://www.npmjs.com/package/jsonld |
| Ruby | JSON-LD Processor en API library | https://rubygems.org/gems/json-ld |
De OSLO tool SpecificationGenerator kan gebruikt worden om vertrekkend uit een domeinmodel een JSON-LD context file te genereren. Verder is de JSON-LD Playground een handige tool om snel JSON-LD objecten te valideren op vlak van syntax.
Case 4: van tabulaire naar linked data
Het merendeel van de bestaande data is enkel beschikbaar in tabulair formaat zoals Excel of CSV bestanden. Omzetten van deze tabulaire data naar linked data kan op verschillende manieren gebeuren. De meest geautomatiseerde manier is om een transformatiescript te programmeren die de relevante triples genereert op basis van de tabulaire data. Deze aanpak vereist programmeerervaring en een specifieke implementatie. Hier stellen we een alternatieve en meer toegankelijke werkwijze voor die steunt op Open Refine.
Open Refine is een tool om met (rommelige) data te werken en laat toe om data op te schonen, te transformeren en uit te breiden. Om eveneens met linked data formaten te kunnen werken, is ook de RDF extensie voor Open Refine nodig. Eenmaal de software geïnstalleerd is, kunnen volgende stappen doorlopen worden om van tabulaire naar linked data te gaan:
- Zorg dat een data- of informatiemodel beschikbaar is. Zie de handreiking voor de analist voor een stappenplan om een dergelijk model te ontwikkelen.
- Orden de tabulaire data zodat elke kolom een eigenschap van het model bevat. Onderstaande figuur illustreert dit voor een fictief voorbeeld waarbij een boek wordt omschreven door middel van een Titel, Beschrijving en een Klantenbeoordeling.
- Importeer de tabulaire data in Open Refine.
- Map de kolommen van de tabulaire data naar de klassen en eigenschappen van het model. Dit kan via de “Edit RDF Skeleton” optie. Een venster getiteld “RDF Schema Alignment” opent waarin manueel kan bepaald worden op welke eigenschap elke kolom moet gemapt worden. In onderstaand voorbeeld wordt de kolom met de boektitels gemapt op dct:title en de beschrijving op dct:description ter illustratie.
- Eenmaal de mapping volledig gebeurd is en alle instellingen gespecificeerd zijn, kan de data geëxporteerd worden als RDF. Dit kan via “Export” > “RDF as RDF/XML”. Onderstaande afbeelding toont het resultaat voor het fictief voorbeeld.


